
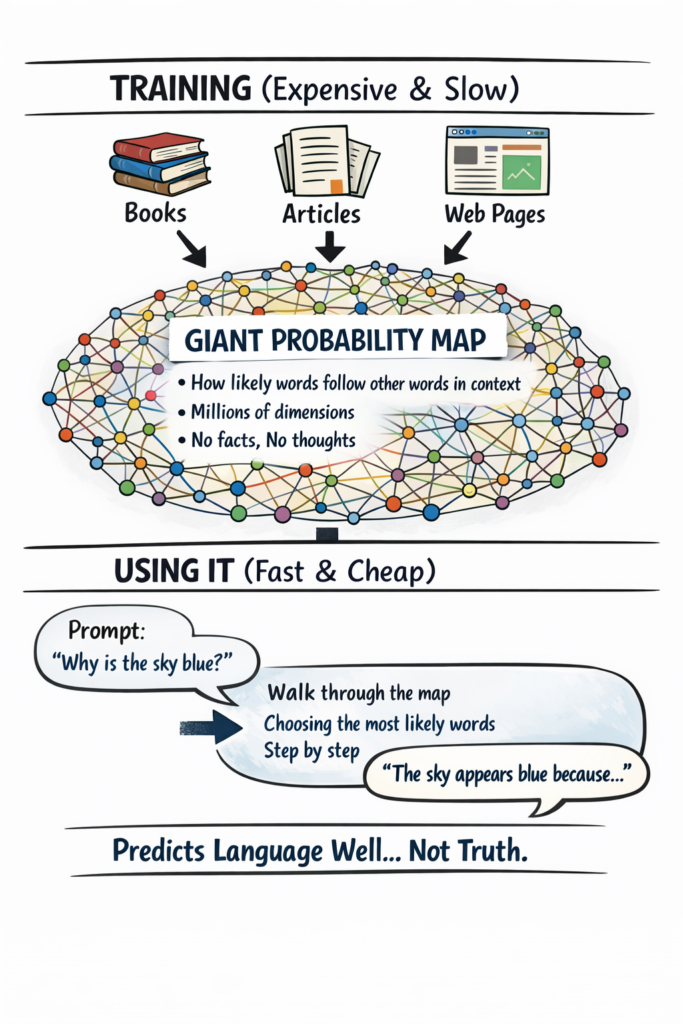
What this diagram is really showing
The most important thing to understand is that a large language model is not a database of facts y not a thinking mind. It is a probability engine.
During training, the system reads enormous amounts of text and compresses what it sees into a very large, multidimensional probability map. This map captures how words, phrases, and ideas tend to follow one another in different contexts. Building that map is slow, expensive, and requires vast amounts of computing power, memory, and storage.
Once the map exists, using the model is relatively cheap. When you enter a prompt, the model doesn’t look anything up or retrieve stored answers. Instead, it starts at a point in this probability space and repeatedly chooses the most likely next word, step by step, until a response is produced. What feels like “intelligence” is really a statistical walk through that map.
Because the model is a compressed representation of its training data, it does not contain everything it has seen. Compression always loses information. This is why language models can generalize and explain ideas well—but also why they can confidently produce incorrect or invented information. They optimize for plausible language, not for truth.
Meaning inside the model is also distributed. No single word, concept, or fact lives in one place. Instead, meaning emerges from patterns spread across thousands of dimensions. This allows flexibility and creativity, but it also means the model has no built-in understanding of correctness, intent, or reality.
Finally, prompts don’t unlock hidden knowledge—they steer the path the model takes through its probability map. Small changes in wording can lead to very different responses, even though the underlying model hasn’t changed at all.
In short: large language models predict language extremely well. That makes them powerful tools—but it also means they should be used with care, especially in situations where accuracy matters.